Recently I was lucky enough to play with Cisco Hyperflex in a lab and since it was funny to play with, I decided to write a basic blog post about the hyper-converged infrastructure concept (experts, you can move forward and read something else 🙂 ). It has really piqued my interest. I know I may be late to the game but better late than never right? 🙂
Legacy IT Infrastructure
Back in the days, you had to have separate silo to maintain a complete infrastructure (it is still true by the way, but it tends to become more and more frequent that networks, servers, and storage are progressively forming a single IT platform …. sorry I meant “cloud”):
- Compute(System and Virtualization)
- Storage
- Network (Network and Security)
- Application
You had to install and maintain multiple sub infrastructures in order to run the IT services in your company.
If you wanted to deploy a greenfield infrastructure for your data center, here is a brief summary of what you needed:
- Physical servers (Owners: System team)
- Hypervisors (Owners: System team)
- Operating system (Owners: System team)
- Network infrastructure (Owners: Network team)
- Routing – Switching
- Security (VPN, Cybersecurity)
- Load Balancers
- Storage arrays (Owners: Storage team)
- Applications for the business to run. (Owners: IT applications team)
Converged Infrastructure and simplification
In the late 2000s, famous manufacturers saw an opportunity to simplify the complexity of the complete data center stack and converged infrastructure was born.
With the emergence of cloud applications, EMC and Cisco created a joint venture Acadia that will later be renamed VCE for (VMware, Cisco, EMC). The purpose of that company was to sell converged infrastructure products. Vblock was the flagship product. As you know, you could buy an already provisioned rack that was customized according to your preferences. The vBlock was composed of the following individual products:
- Storage Array: EMC VNX/VMAX
- Storage Networking: Cisco Nexus, Cisco MDS
- Servers: Cisco UCS C or UCS B
- Networking: Cisco Nexus
- Virtualization: vSphere
- vDS with Cisco Nexus 1000v
- MPIO with EMC PowerPath/VE
VCE was in charge of configuring (or customizing I should say) the vBlock according to your need and preference.
Once the network was delivered, you “just” had to plug it in your data center networking infrastructure and everything should be connected. Servers were ready to be deployed.
Going that way, you could save time and trouble. Agility is also a big selling point for these kinds of architectures.

Hyper-converged Infrastructure and horizontal scaling
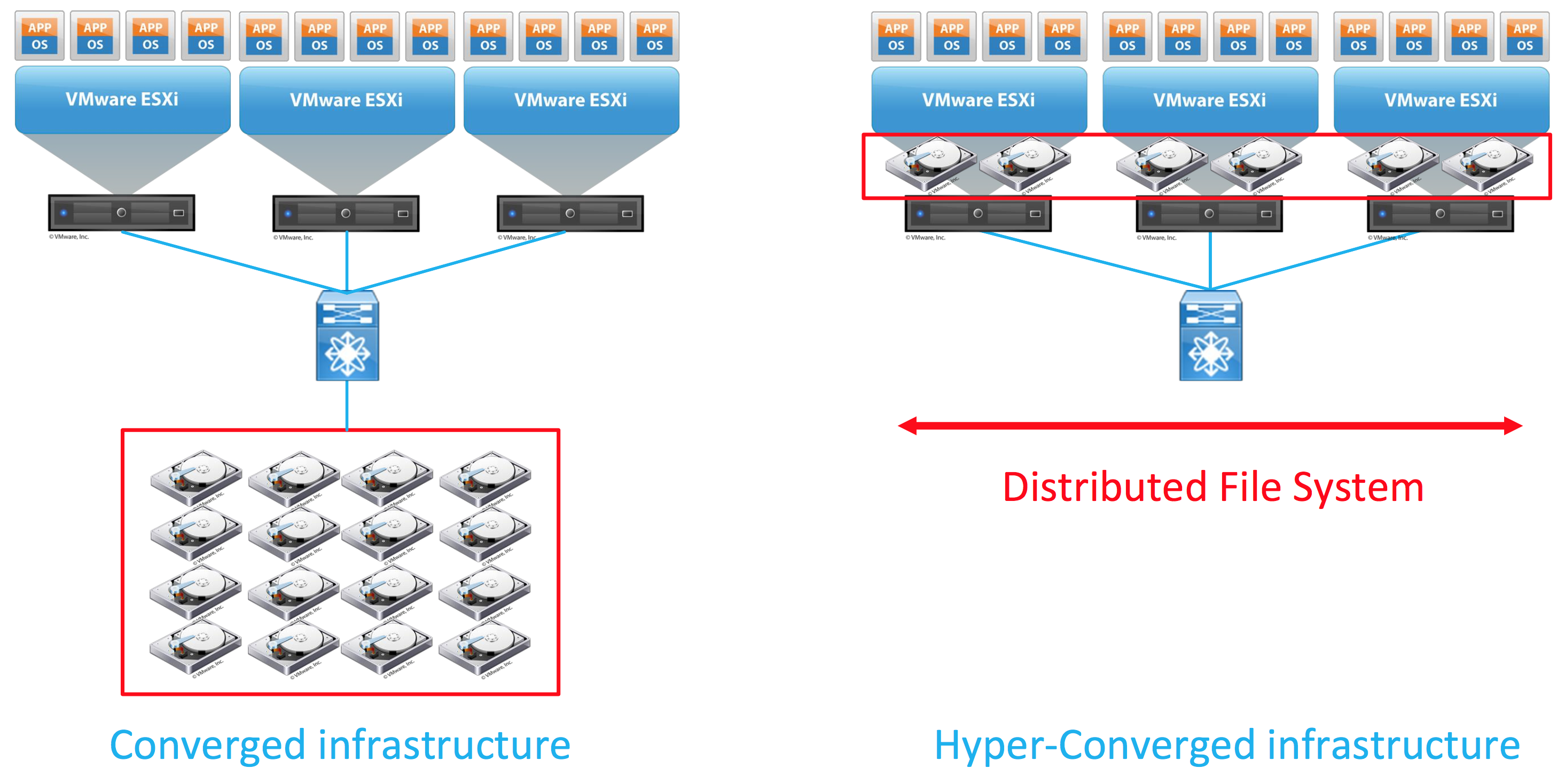
Hyper-converged is a term that has been rolling since 2012. The main difference between converged and hyper-converged infrastructure is definitely the storage
- Converged infrastructure:
- Centralized array accessible using a traditional storage network (FC with FSPF or ISCSI/NFS)
- Hyper-converged infrastructure:
- Distributed drives in each servers forming a centralized file system.
Hyper-converged system has the ability to be adaptable. The way it scales is horizontal while reducing the footprint by a significant amount. If you just want to try it, just perform a setup with few hosts and if the solution works for you, just add nodes to the cluster horizontally and you will increase your performance and redundancy. This way, you can consolidate your compute and storage infrastructure.
Horizontal scaling is a familiar concept for many network engineers (Clos Fabrics anyone?)
In my opinion, it is a natural evolution of the Data Center compute and storage infrastructure.
- Nutanix
- Simplivity
- Cisco
- Pivot3
- Dell-EMC (With Both VXrail and VXrack)
- Hewlett Packard
- Huawei
- Scale Computing
- VMware
- Stratoscale
My next post will be about deploying a Cisco Hyperflex infrastructure.
Thanks for reading !